Our every visit to the doctor is built upon evidence
Let’s imagine that you visit a doctor due to chronic sleep problems (chronic insomnia). In this case, the doctor is a sleep specialist and follows the latest research, basing his conclusions on a comparative effectiveness review of treatments for insomnia. The review shows that there are two effective treatments: Cognitive behavioural therapy for insomnia (CBT-I) (moderate evidence) and various sleeping pills (low evidence).
Comparative effectiveness reviews and systematic reviews (in future sentences, both are referred to just as systematic reviews) are widely held as the gold standard of evidence in many sciences. In traditional reviews, authors typically collect together the studies they already know or can easily identify. This often leads to overemphasising studies that are in line with his/her own hypothesis. With systematic reviews, authors first specify a research question and then they have to search, identify, take into account and potentially statistically sum up all studies according to a carefully pre-planned strategy.
It is often illustrated that in systematic reviews, individual studies are the “participants” of the meta-analysis. Often, and in the case of this blog, systematic reviews are used to determine how effective on average the intervention is (e.g. how many minutes the sleep time of insomniacs is increased on average).
What is GRADE?
The most prominent framework for evaluating the effectiveness of systematic reviews is GRADE (Grading quality of evidence and strength of recommendations). GRADE is used to rate the certainty of evidence for a treatment efficacy from high to very low. The GRADE system takes in two types of studies: randomized controlled trials (RCTs) and observational studies (also including non-randomized trials). In RCTs, one group of participants is randomized to a treatment and another group to placebo or an alternative condition. In observational studies, participants that took part in the treatment are simply compared to placebo, no treatment, or an alternative condition without randomization. Observational studies can be conducted as trials where participants are recruited via email or other means but are not randomized, or they can be conducted using data that is collected during routine work in hospitals or other medical centres. Studies without a control group can also be counted as observational studies, although they are less often used in systematic reviews that use GRADE assessment.
Observational studies suffer from a problem of confounding. If sleeping pills, on average, worked better compared to placebo pills, it can always be possible that it only worked because the comparison group were younger and the drug only works for young people, or because the treatment group had a placebo effect. Although there are many statistical methods to control for confounding, no method can fully account for unknown confounding factors – that may be the real reason for the difference between treatment and control group. Randomized studies are considered the gold standard as successful randomization takes out both known and unknown confounding factors. Interestingly, in economics, there exists methods that use natural random effects to control for confounding.
The GRADE criteria
In the GRADE system, the evidence is therefore initially set to either high (if included studies are randomized studies) or low (if they are observational studies). There are then 5 criteria that can be used to downgrade one, two, or in the case of indirectness, sometimes three steps. These are:
- Risk of bias in individual studies – e.g. methodological issues in included studies such as inadequate blinding (participants knew they were in control/treatment group)
- Inconsistency of results between studies
- Indirectness of evidence – e.g. participants were children although the systematic review was about adults
- Imprecision – results were not statistically significant, or the effect was clinically important once the studies were meta-analysed
- Publication bias – result was biased due to a file-drawering effect, as studies not showing a statistically significant effect are less likely to be published.
Additionally, observational studies starting at low can be upgraded based on 3 criteria: large effect, dose-response effect and “Effect of all plausible confounding factors would be to reduce the effect (where an effect is observed) or suggest a spurious effect (when no effect is observed)”. An example of the ‘dose-response effect’ refers to a finding that a larger dose of medicine leads to better treatment outcomes. The last criteria is complex but refers to situations where there is a bias (e.g. all doctors are told about a potential side effect) among clinicians to overdiagnose certain side effects but nevertheless no increased number of side effects is found in the studies.
If you were to look at a systematic review for chronic insomnia with a GRADING of moderate for sleep quality outcome for CBT-I, we would find out that there are many gold standard studies, randomized controlled trials conducted, that have compared CBT-I against control (placebo) condition. Therefore, a GRADING of moderate for sleeping pills would be achieved because the evidence was downgraded from high to moderate using one of the following 5 criteria for downgrading evidence: Risk of bias (in individual studies), Inconsistency, Imprecision, Indirectness or Publication bias.
On the other hand, when it comes to sleeping pills it might be possible in a hypothetical scenario (even though in this case that is not true) that instead of the gold standard RCT we would only have observational studies with no individual randomization. Therefore, the evidence would have started for sleeping pills from low, and as none of the 3 criteria for upgrading the evidence for observational studies were fulfilled (large effect, dose-response effect, or plausible confounding/bias would have led to over/underestimation of the effect) the evidence would stay low.
Summary of GRADE for systematic reviews
The table below from the GRADE handbook provides a very useful summary of the 5 downgrading and 3 upgrading criteria:
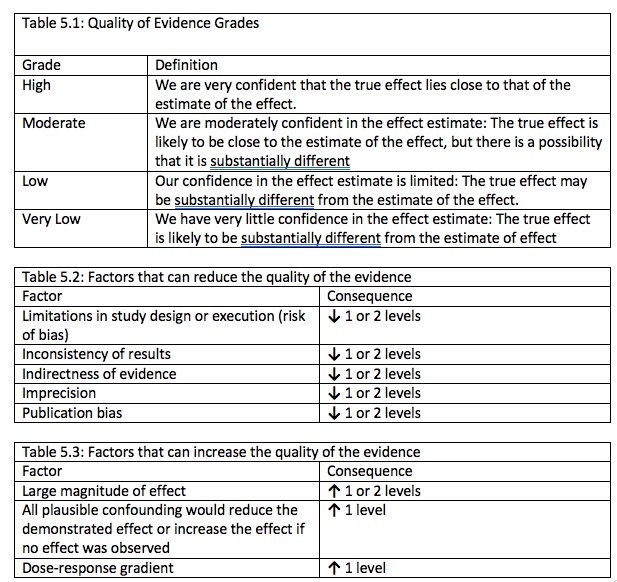
Schünemann, H., Brozek, J., & Oxman, A. (2013). GRADE handbook for grading quality of evidence and strength of recommendations. Updated October.
This blog aims to clarify the structure of GRADE the most advanced evidence hierarchy (or evidence base hierarchy) in evidence-based medicine (Blunt, 2015).
During the last 15 years, the outlined GRADE system has become a widely used global standard. It is used by guideline makers, such as the World Health Organization. As Blunt points out, the term global standard may be slightly overconfident, as many guideline makers who have started to use GRADE still use other systems at the same time. However, it is the single most prominent system available and is constantly developing and providing a platform for co-operation for different guideline makers (Centers for Disease Control and Prevention (CDC), 2011).
For example, in recent years, GRADE has become a mandatory element for newly published systematic reviews conducted by Cochrane, widely held as the most prominent evidence-based medicine organization. You can read more about Cochrane’s Strategy 2020 here.
Useful resources:
www.gradeworkinggroup.org: For visual clarification, the GRADE website provides videos and articles to get started.
Understanding GRADE: an introduction. Goldet, G & Howick J (2013)
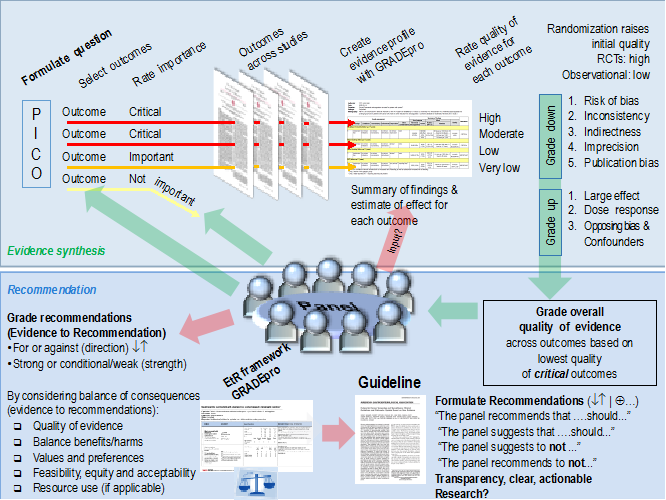
A visual explanation of GRADE from the gdt GRADE pro website
{kind=link}
References
The post GRADE and quality of evidence appeared first on Students 4 Best Evidence.
No comments:
Post a Comment